
Building a dataset of Python versions with regular expressions
In this post, I’ll teach you how to use pandas, requests, and regular expressions to create a dataset of every Python version and its release date.
I’ll explain the code in detail so that you can follow along even if you have no experience with these tools.
By the end of this post, you’ll be familiar with the basic syntax of regular expressions and how it can be used as part of a web scraping project!
Here’s what I’ll cover:
- Why learn regular expressions?
- Goal: Build a dataset of Python versions
- Step 1: Read the HTML with requests
- Step 2: Extract the dates with regex
- Step 3: Extract the version numbers with regex
- Step 4: Create the dataset with pandas
- Going further with regular expressions
Why learn regular expressions? 🎓
I know that regular expressions (also known as “regex”) can be intimidating. It looks like a cryptic language composed of letters, numbers, dashes, dollar signs, backslashes, and other punctuation marks.
However, regex is also incredibly powerful, and applicable to so many problems!
Here are a few of the tasks that regex can help you to accomplish:
- Building a dataset from an unstructured text source like raw log files, HTML pages, PDF documents, or OCR-generated text
- Cleaning and standardizing your datasets
- Finding and replacing text using sophisticated patterns
- Extracting useful features for Machine Learning
In other words, learning regex will help you to become a more versatile and valuable data scientist! 👨🔬
Below, I’ll deconstruct a few regular expressions, and you’ll see that they are not as puzzling as they might first appear. 🧩
Goal: Build a dataset of Python versions 🐍
Let’s say that you wanted to build a dataset of every Python version and its release date. This python.org web page has all of the data you need:

Our task is to turn this into a structured dataset.
Step 1: Read the HTML with requests 📖
We can start by reading the source of the web page (meaning the HTML) into Python using the requests library:

Here’s a small portion of the HTML, which is stored in the r.text string:
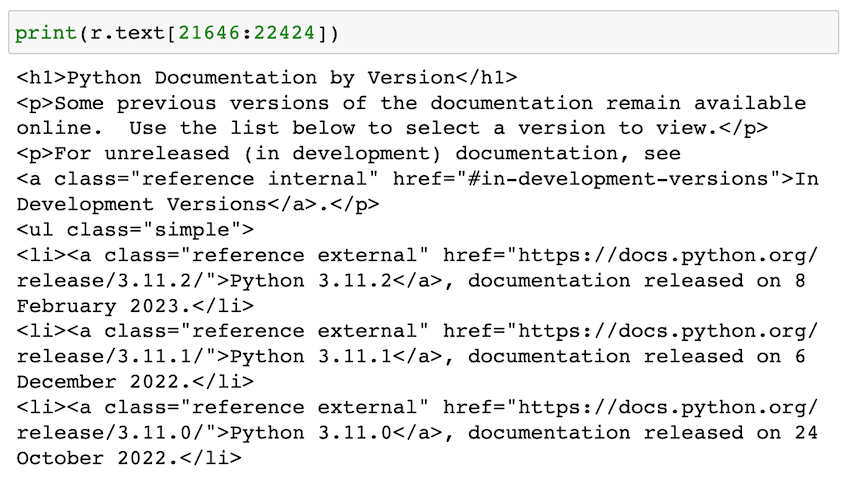
In order to parse the HTML into something useful, we’ll use regular expressions.
Step 2: Extract the dates with regex 📆
Here’s how we can use regex to extract the Python release dates:
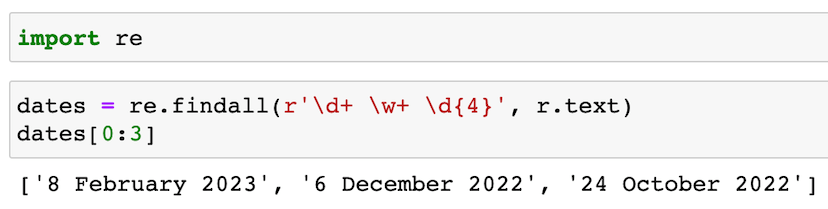
We imported the built-in re module, and then used its findall function to search the r.text string for all occurrences of a regex pattern.
This is the pattern we searched for: \d+ \w+ \d{4}
Here’s how to decode the pattern:
\dmeans “digit character” (0 through 9)\wmeans “word character” (letter, digit, or underscore)+means “one or more”{4}means “exactly 4”
Thus the pattern \d+ \w+ \d{4} can be read like this:
Find 1 or more digits, then a space, then 1 or more word characters, then a space, then 4 digits.
And that’s how it found the dates!
In case you were wondering, the r before the string creates a “raw string”, which is important when writing regex patterns so that the backslashes are handled properly by the Python interpreter.
Step 3: Extract the version numbers with regex 🔢
It’s a bit more complicated to extract the version numbers because some have 2 parts (1.5), some have 3 parts (1.5.1), and some have a letter (1.5.1p1):

Here’s what we’ll do:

This is the pattern we searched for: Python (\d.+?)<
Here’s how to decode this:
\dmeans “digit character”.means “any character except newline”+means “one or more”?means “make the match as short as possible”()means “only return this part of the match”
Thus the pattern Python (\d.+?)< can be read like this:
Find “Python”, then a space, then 1 digit character, then 1 or more of any character (but make the match as short as possible), then “<”, and only return the part in parentheses.
And that’s how it found the versions!
In case you were wondering, the angle bracket (meaning the <) helps us to find the version number since it’s always just before the </a> tag in the HTML.
Step 4: Create the dataset with pandas 🐼
At this point, we can create a pandas DataFrame by zipping the two lists together and assigning names to the columns:
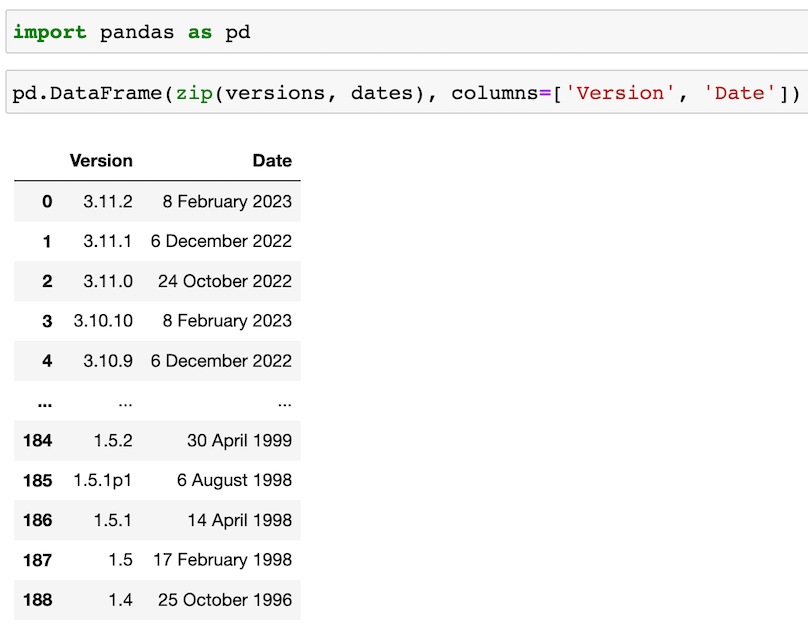
Pretty cool, right? 😎
Here’s the code from this post in case you want to play around with it!
Going further with regular expressions 🚀
This example is just a tiny preview of the versatility of regular expressions!
If you want to unlock the full power of regular expressions, I’d encourage you to take my new course, Become a Regex Superhero.
In the course, we’ll slowly build from the absolute basics of regular expressions all the way up to complex topics. We’ll take the time to practice everything we’re learning, which will help to solidify each concept.
By the end of the course, you’ll have gained a powerful skill that will significantly improve your ability to process and manipulate text data!
You can learn more and enroll here, or just post a comment below if you have any questions!