
Machine Learning with Text in Python
Is this Data School course right for you?
Are you trying to master machine learning in Python, but tired of wasting your time on courses that don't move you towards your goal? Do you recognize the enormous value of text-based data, but don't know how to apply the right machine learning and Natural Language Processing techniques to extract that value?
In this Data School course, you'll gain hands-on experience using machine learning and Natural Language Processing to solve text-based data science problems. By the end of the course, you'll be able to confidently apply these techniques to your own data science problems.
Ryan Cranfill (Data Scientist): "The course was a perfect introduction to machine learning with text, and I was able to apply topics covered during the first week to my work. Kevin does a great job of breaking down complex topics and providing a practical, real-world context for them."
Jump to: Course Description - Course Outline - FAQs
How is it different from other online courses?
Most data science courses suffer from a host of problems: They're poorly taught, lack the necessary depth, and include unexplained or broken code. They don't teach you how to apply what you're learning, and when you do apply it, there's no way to know how well you're doing.
But in this course, we'll go deep into machine learning with text, focusing on application from day one. We'll spend most of our time writing Python code, and you'll understand how every single line relates to the problem we're solving. You'll practice what you're learning through carefully crafted lessons and assignments.
At the end of this course, you'll leave with valuable machine learning experience, high-quality code that you can reuse to solve future text-based problems, and a wealth of curated resources to help you deepen your understanding of each course topic.
Cliff Baker (Statistician): "You won't find a better course to learn about NLP and machine learning in Python anywhere else! Kevin has a way of making difficult topics very accessible and understandable. I was able to quickly apply much of the theory and code regarding NLP and machine learning from this course to my own job."
Course Description
In this self-paced online course, you'll learn how to build effective machine learning models using text-based data to solve your own data science problems. The course includes:
- 14 hours of high-quality instructional videos
- Well-commented lesson notebooks in Jupyter format (also available as Python scripts)
- Substantial homework assignments (with provided solutions) to help you practice everything you're learning
- A list of readings and videos to help prepare you for each class
- Links to 100+ carefully selected resources to deepen your understanding of course topics
- Lifetime access to all course materials
- Money-back guarantee (within 30 days)
Course Outline
Each module includes 2 to 4 hours of instructional videos, 1 lesson notebook, 1 to 2 homework assignments, and 15 to 20 supplementary resources.
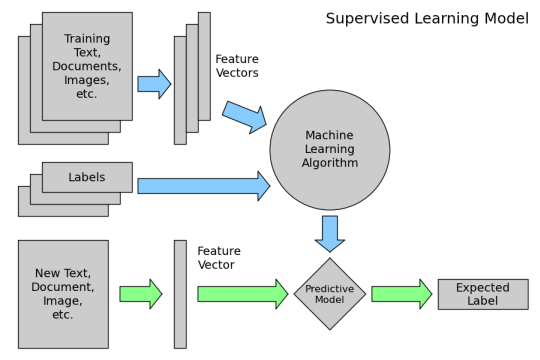
Module 1: Working with Text Data in scikit-learn
By the end of this module, you'll be able to confidently perform the basic workflow for machine learning with text: creating a dataset, extracting features from unstructured text, building and evaluating models, and inspecting models for further insight. You'll also gain an understanding of Unicode, enabling you to troubleshoot encoding-based errors.
- Extracting features from unstructured text using
CountVectorizer - Building a
MultinomialNBmodel for text classification - Examining a model for further insight
- Model evaluation:
accuracy_scoreconfusion_matrixroc_auc_score
- Comparing
MultinomialNBwithLogisticRegression - Building a new dataset from individual text files using
pandas - Unicode basics
- Handling Unicode errors
Module 2: Applying Natural Language Processing Techniques to Machine Learning
By the end of this module, you'll be able to apply a handful of Natural Language Processing techniques to machine learning problems in order to improve the effectiveness of your models. You'll also learn how to perform sentiment analysis and build a simple document summarization tool for your own corpus of text.
- What is Natural Language Processing (NLP)?
- NLP terminology and examples
- Tuning
CountVectorizerfor better model performance:- n-grams
- stop words
- corpus-specific stop words
- minimum document frequency
- Term Frequency-Inverse Document Frequency (TF-IDF) using
TfidfVectorizer - Text summarization
- Sentiment analysis using
TextBlob
Module 3: Parsing Text Data Using Regular Expressions
By the end of this module, you'll be able to extract text features from messy data sources using regular expressions. You'll learn the basic rules and syntax that can be applied across programming languages, and you'll master the most important Python functions and options for working with regular expressions.
- Basic rules and principles
- Searching with
re.search - Metacharacters
- Greedy and lazy quantifiers
- Match groups
- Character classes
- Alternatives
- Substitution with
re.sub - Anchors
- Option flags
- Efficiently searching for multiple matches with
re.findall - Improving performance with
re.compile - Writing readable regular expressions with
re.VERBOSE
Module 4: Workflow for a Text-Based Data Science Problem
By the end of this module, you'll be able to create an end-to-end workflow for solving a text-based data science problem using scikit-learn and pandas. You'll gain experience with data exploration, feature engineering, proper model evaluation, model tuning, and generating predictions for new observations.
- Data exploration and visualization
- Feature engineering using
pandas - Custom tokenization using regular expressions
- Multi-class classification
- Model evaluation:
train_test_splitcross_val_scoreDummyClassifier
- Searching for optimal tuning parameters using
GridSearchCV - Chaining steps into a
Pipeline - Making predictions for out-of-sample data
Module 5: Advanced Machine Learning Techniques
By the end of this module, you'll be able to apply advanced machine learning techniques to improve the accuracy of your models and the efficiency of your workflow. You'll learn how to build and tune a multi-step, multi-layer machine learning pipeline, as well as how to ensemble and stack your models.
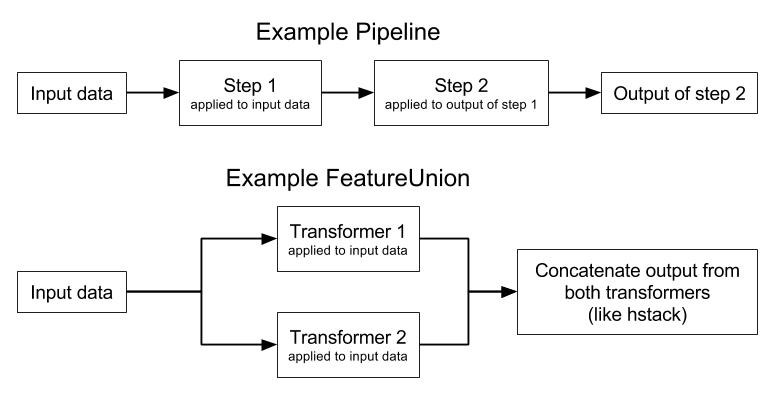
- Using a
Pipelinefor proper cross-validation - Tuning a
PipelinewithGridSearchCV - Efficiently searching for tuning parameters using
RandomizedSearchCV - Stacking sparse and dense feature matrices using
SciPy - Combining the results of multiple feature extraction processes using
FeatureUnion - Building multi-level pipelines and feature unions
- Building custom transformers using
FunctionTransformer - Improving classifier performance through ensembling
- Unsupervised document clustering using cosine similarity
- Basic strategies for model stacking
Miguel Angel Regalado (Digital Analytics Consultant): "Practical and easy-to-follow course on advanced topics in machine learning. Videos are incredible, full of tips and resources. Outstanding teaching skills by Kevin and his team."
FAQs
Is this a beginner course?
No. This is an intermediate course, with specific prerequisites:
- You should be comfortable working in Python.
- You should understand the basic principles of machine learning.
- You should be comfortable using
scikit-learn. - You should have at least limited experience with
pandas. - No knowledge of advanced mathematics is required.
How do I know whether I'm ready for the course?
Review the content from my free scikit-learn course and my pandas video series. If you are comfortable with most of the content, you are ready for the course. If you are new to Python, I recommend enrolling in Python Essentials for Data Scientists first. If you are unsure whether you meet the course requirements, please email me!
What types of people have taken this course?
Here are the job titles of some of my past students:
- Data professionals: Data Scientist, Director of Data Science, Statistician, Business Intelligence Developer, Analytics Manager, Quantitative Analyst, Data Analytics Architect, Data Journalist
- Engineers: Senior Software Engineer, Data Engineer, Network Engineer, Back-End Developer, Director of Engineering, Air Pollution Engineer
- Scientists: Artificial Intelligence Researcher, Chief Scientist, Research Associate, Computational Linguist, Applied Mathematician, Psychiatrist, Computational Chemist, Geophysicist, Cognitive Scientist
- Other: Graduate Student, Product Manager, Security Consultant, Business Analytics Instructor, Creative Director, Corporate Strategist, Web Developer, Internet Marketer, Lawyer, Entrepreneur, System Administrator, Project Manager, Python Instructor, Kaggle Master
Jose Navarro (Machine Learning Engineer): "I used to work as a software developer and your course helped me to move on. I now have a job in the NLP/Machine Learning field which I am more passionate about."
Why should I learn how to work with text?
Most knowledge created by humans is raw, unstructured text. By learning how to transform text into data that is usable by machine learning models, you drastically increase the amount of data that your models can learn from.
What will I be able to do by the end of this course?
- Convert unstructured text into a format that is suitable for machine learning
- Apply appropriate model building, model evaluation, and feature engineering techniques to text-based problems
- Tune the feature extraction and model building pipeline for optimal performance
- Build a custom sentiment analysis or document summarization tool for your own corpus of text
- Extract features from messy data sources using regular expressions
- Utilize a more efficient workflow with scikit-learn and pandas
Charles Franzen (Assistant Education Manager): "Kevin's courses are focused and coherent. Tools learned each week build upon and complement one another, and the classes culminate with a larger-scale project that shows how what you've learned can come together. I learned a great deal, and highly recommend Data School to those looking to explore machine learning tools in greater depth."
Which version of Python do I need for the course?
Both Python 2 and Python 3 are perfectly acceptable.
What libraries will we be using?
The majority of the content will use scikit-learn, though we will also use pandas to help us load, prepare, and visualize data. We will use the built-in re module for regular expressions. We will also make limited use of NumPy, SciPy, Matplotlib, Seaborn, and TextBlob.
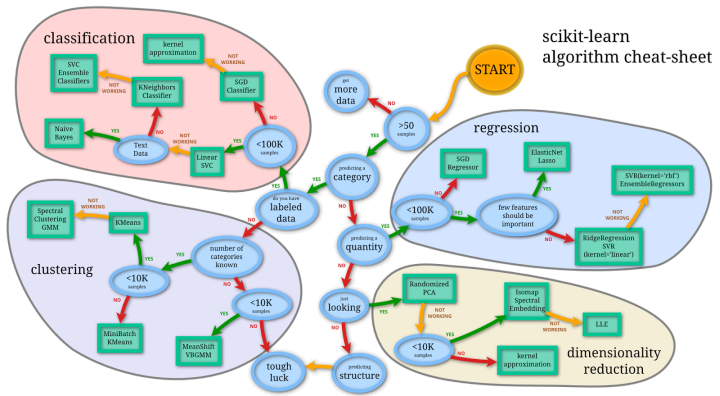
Why doesn't the course use NLTK or spaCy?
This course focuses on supervised Machine Learning. scikit-learn is by far the best Python library for solving most Machine Learning problems, including those problems in which the input data is text. In contrast, NLTK and spaCy are Natural Language Processing (NLP) libraries which specialize in language-oriented tasks such as part-of-speech tagging, dependency parsing, named entity recognition, and so on. Although basic NLP techniques are covered in this course, Machine Learning is still the primary focus, and thus scikit-learn is the best choice.
Is the course material up-to-date?
Since creating the course in 2016, I've spent hundreds of hours refining and updating it based on student feedback. In December 2019, I updated the course code to use the latest version of every library, including Python 3.7 and scikit-learn 0.21. All of the processes I teach in the course are still the ones I recommend today, with the exception of one small section of module 5. (However, I added an addendum notebook in May 2020 to demonstrate the current best practices for that specific section.)
Chandler McCann (Data Science Practice Lead): "Kevin is an extremely knowledgeable teacher who cares about his students and puts a ton of preparation into his courses and materials. Kevin's approach to teaching data science is logical, well-structured and accessible. I highly recommend this course."
How is this course different from other online courses?
- The course is application-focused, providing you with skills that you can immediately apply to your own data science problems.
- The course is taught by an experienced data science instructor.
- The lesson notebooks are carefully crafted and will serve as excellent reference materials for years to come.
- All of the code is thoroughly explained, well-written, and compatible with both Python 2 and 3.
- The homework assignments enable you to immediately practice what you have learned, and the included solutions are fully commented.
- The 100+ post-class resources build directly on the course material, and will help you to explore each topic in more depth.
- You will have lifetime access to all course materials.
Dr. Kathleen Perez-Lopez (Senior Data Scientist): "In Machine Learning with Text, Kevin Markham does a superb job walking you through this topic at an intermediate level. The classes were totally engrossing. His homework assignment for each class steps you through a process so that you don't get stuck at any stage. He points to a tremendous amount of carefully curated supporting material. I'm looking forward to his next offering."
Who is the instructor?
The course instructor is Kevin Markham (me!): Founder of the Data School blog and YouTube channel and former Lead Data Science Instructor for General Assembly in Washington, DC. I have more than 400 hours of classroom experience teaching data science in Python, and more than 1,000 hours of experience creating data science educational materials, mentoring data science students, and training other data science instructors.
Can I see a sample of the course content?
I previously presented 3-hour tutorial based on a portion of this course. Below is a recording that should give you a good idea of my teaching style.
Tsering Paljor: "Hands down the best machine learning presentation I've seen thus far."
How much does the course cost?
Enrollment in the course costs $299.
Leo Lillard (Sr. Data Scientist): "If you like Kevin's material, you will love his classes. Full of information that will take your Python skills to the next level and will leave you wanting more. This will be the best $300 you spend on training."
Jeff Weakley (Creative Director): "Stop reading this and sign up now! Kevin isn't just a programmer/data scientist, he's a great teacher. If I had paid a lot more for this class, it would still have been worth it. After taking a lot of other online courses, I feel like I'm finally getting valuable skills, tools and info I can use and financially benefit from."
Do you offer any discounts?
Yes! I offer a Purchasing Power Parity discount to make my courses more affordable to people living in the developing world. I also offer discounts to full-time students and to anyone experiencing a significant financial hardship due to the pandemic. Please email me and I'd be happy to send you the appropriate discount code.
What happens when I enroll in the course?
Shortly after enrolling in the course, you will be given access to all course materials. You can work through the course at your own pace.
How much time will the course take to complete?
Past students have said that they spent anywhere from 40 to 60 hours working through the course.
How long will I have access to the course?
You will have lifetime access to all course materials.
Wolfgang Guba (Computational Chemist): "I now feel very confident to use pandas and scikit-learn for machine learning. I can highly recommend Kevin's course, he is a great teacher and can explain difficult concepts really well!"
What will happen at the end of the course?
You'll leave the course with valuable machine learning experience, high-quality code that you can reuse to solve future text-based problems, and a wealth of curated resources to help you deepen your understanding of each course topic.
Will I receive a certificate of completion?
Yes, you will receive an official certificate of completion from Data School after completing the course.

Have students been happy with the course?
In an anonymous post-course survey, students were asked to rate the course on a scale from 1 (poor) to 5 (excellent). On average, students have rated the course 4.70 for "quality of content", 4.84 for "quality of instruction", and 4.60 for "overall value provided by the course". In addition, 93% of students reported that the course had "helped them to make progress towards their personal or professional goals."
Asif Mehedi (Research Associate): "Having known Kevin from his YouTube videos on scikit-learn and more recently pandas, I've long admired his ability to explain difficult concepts in clear language. This new course was no exception. I now feel prepared to use machine learning in my text analysis projects."
What if I'm not happy with the course?
I offer a "Love it or leave it" guarantee: If you don't love the course, I'm happy to give you a full refund, no questions asked, if you cancel within 30 days of purchase.
Dr. Jovian Lin (Senior Research Scientist): "Kevin is the teacher that everyone needs. He makes complicated concepts simple through a meticulously well-crafted course plan."
What if I need help with the course?
You can post a question below any lesson, and I'll do my best to respond!
I have more questions...
Please email me. I'm happy to answer all of your questions!
Harvey Summers (Data Management Specialist): "I've taken a couple of courses with Kevin and recommend him highly. He does a great job of making the complex simple, and it's amazing how much you learn in just a few weeks. The best course on machine learning I've taken so far!"